
Understanding Apache Hadoop Ecosystem and Components
Hadoop is an ecosystem of Apache open source projects and a wide range of commercial tools and solutions that fundamentally change the way of big data storage, processing, and analysis. The most popular open source projects of Hadoop ecosystem include Spark, Hive, Pig, Oozie and Sqoop.
Apache Hadoop Ecosystem Projects
Apache Spark
An open-source and fast engine for large-scale data processing. It supports data streaming and SQL, machine learning and graph processing.
Apache Hive
A data warehouse that runs on the top of Apache Hadoop. Apache Hive provides SQL like syntax for reading, writing and managing large datasets stored in distributed storage (structured data).
Impala
An open source parallel processing SQL query engine that runs on Apache Hadoop used for querying data, stored in HDFS and Apache HBase.
Apache Drill
An open-source, schema-free SQL Query Engine for Hadoop, NoSQL and Cloud Storage.

Apache HBase
An open source, nonrelational, distributed database runs on the top of HDFS. HBase is used for random, real-time read/write access to your Big Data.
Spark MLib
A scalable machine learning library based on the top of Spark Core.
Mahout
Mahout is a machine learning library and used for clustering, classification and collaborative filtering of data. It is based on top of distributed data systems, like MapReduce.
R
R is a programming language used for data visualization, statistical computations and analysis of data.
Apache Solr
An open source search platform used for full-text search, hit highlighting, faceted search, real-time indexing, dynamic clustering, database integration etc.
Apache Pig
A high-level platform for handling any kind of data and runs on Hadoop. It uses PigLatin language to write programs and enables us to spend less time in writting map-reduce programs for analyzing large data sets.
Apache Kafta
A distributed publish-subscribe messaging system designed for processing of real-time activities stream data (logs, social media streams).
Apache Sqoop
A tool to transfer bulk data between Hadoop and structured data stores such as relational databases.
Apache Storm
A distributed real-time processing system for analyzing stream of data and doing for realtime processing what Hadoop did for batch processing.
Apache ZooKeeper
An open source configuration, synchronization and naming registry service for large distributed systems.
Apache Ambari
An open source web-based management tool that runs on the top of Hadoop and responsible for managing, monitoring and provisioning the health of Hadoop clusters
Cloudera Manager
A commercial administration tools provided by Cloudera Inc. that runs on the top of Hadoop and responsible for managing, monitoring and provisioning the health of Hadoop clusters
Hadoop Components
There are three main core components of the Apache Hadoop framework - HDFS, MapReduce and YARN.
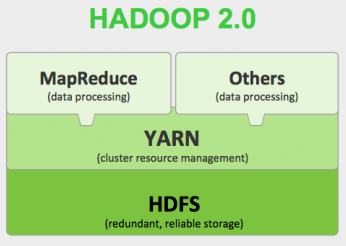
HDFS
A primary storage system of Hadoop. HDFS store very large files running on a cluster of commodity hardware. It works on principle of storage of less number of large files rather than the huge number of small files.
MapReduce
A software programming model for processing large sets of data stored in HDFS. It process huge amount of data in parallel.
YARN
YARN is the processing framework in Hadoop. It provides Resource management, and allows multiple data processing engines, for example real-time streaming, data science and batch processing.
Commercial Apache Hadoop Distributions
Hadoop is open source free platform and can be downloaded from www.hadoop.apache.org. There are also commercial distributions that combine core Hadoop technology with additional features, functionality and documentation. The most popular commercial distribution of Hadoop include Cloudera, Hortonworks, and MapR for Hadoop development, production, and maintenance tasks
Cloudera
Cloudera Inc. was founded by big data geniuses from Facebook, Google, Oracle and Yahoo in 2008. It was the first company to develop and distribute Apache Hadoop-based software, but now released as open source software.

MapR
MapR was founded in 2009 and one of the leading vendors of Hadoop. This provides an Apache Hadoop distribution, a distributed file system, database management system, a set of data management tools and other related software.

Hortonworks
Hortonworks was founded in 2011 and quickly emerged as one of the leading vendors of Hadoop. This provides an open source platform based on Apache Hadoop for analysing, storing and managing big data.

What do you think?
Thank you for your time, I hope you enjoyed this article and found it useful. Please add your comments and questions below. I would like to have feedback from my blog readers. Your valuable feedback, question, or comments about this article are always welcome.
Take our free skill tests to evaluate your skill!

In less than 5 minutes, with our skill test, you can identify your knowledge gaps and strengths.






